V-RAGは視覚言語モデル(VLM)を活用した次世代型のRAG(Retrieval-Augmented Generation)システムで、PDFのページ全体を直接ベクトル化し、従来のRAGで必要だった煩雑なテキスト分割プロセスを省略しています。
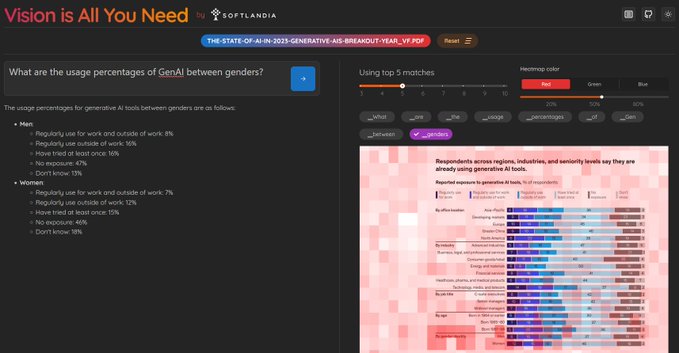
特徴
- 文書のレイアウト情報保持
- PDFのページをそのまま画像としてベクトル化するため、表やグラフ、レイアウトといった情報も正確に保存・処理可能。
- 高速で精密なインデックス作成
- 従来手法に比べ、文書のインデックス作成が迅速で高精度。
- 主要コンポーネント
- PyPDFium: PDFを画像に変換。
- ColPali: ページ画像からベクトル埋め込みを生成。
- Qdrantデータベース: ベクトルデータの保存と検索。
- GPT-4 Vision: クエリを処理し、文脈に合った回答を生成。
主な用途
- 複雑なビジュアルドキュメント(技術レポート、研究論文、データチャート)
- 表やグラフを含むPDFファイルの効率的な検索・利用
詳細とプロジェクトページ
GitHubリンク: V-RAG
RAGの新しい可能性を切り開くシステムとして、特に視覚情報を活用するアプリケーションで有用です!