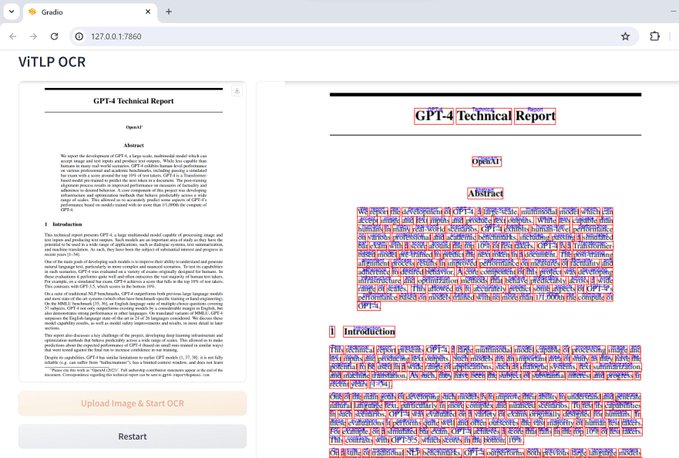
AIを活用したスマートドキュメント処理モデル「ViTLP」について:
「ViTLP」は、OCRによるテキストの位置特定と認識をネイティブに実行し、さらにドキュメント全体のレイアウト構造を理解できるモデルです。
主な特徴:
- エンドツーエンド処理: 画像入力から直接構造化出力までを一貫して処理
- 高い精度: 一般的な4090環境では1ページあたり5~10秒で処理可能
- 統合機能: テキスト認識、レイアウト分析、構造理解を一体化し、原文書のレイアウト構造を保持
- ローカルデプロイ対応: オフライン環境での使用も可能
詳細はGitHubリポジトリをご覧ください。