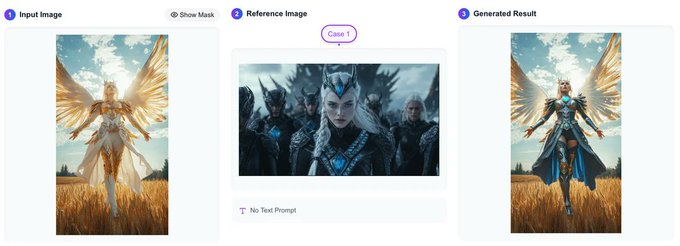
Qwen2vl-Flux モデルが登場しました!FLUX モデルに組み込まれていた T5 モデルを Qwen2VL に置き換えることで、マルチモーダル画像理解とプロンプト解釈の能力が大幅に強化されました。
主な特徴
- テキスト不要の画像生成
- テキストプロンプトなしで画像から直接新しい画像を生成可能。
- 画像とテキストの融合生成
- IPAのように、画像とテキストを組み合わせて特定のスタイルを持つ画像を生成。
- GridDot コントロールパネル
- 細かなスタイル抽出と調整が可能なインターフェイスを提供。
- ControlNet の統合
- Depth と Canny のコントロールをサポートし、生成結果をより高度に制御可能。
使用例
- ビジュアルプロンプトベースのコンテンツ生成
- テキストと画像の複合スタイルを活用したクリエイティブなデザイン
- 精密なスタイル調整やコンセプトアート作成
リソースリンク
多モーダル生成と高精度な画像理解が求められる用途に最適な選択肢です。ぜひ試してみてください!