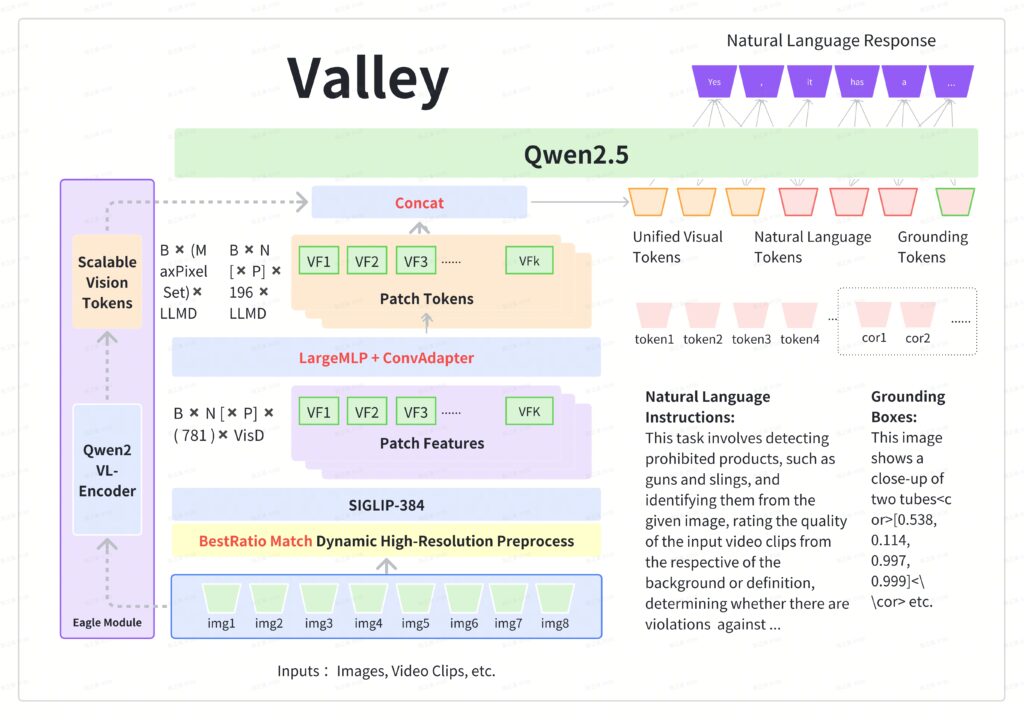
最新の多モーダル大規模モデル「Valley」を紹介します。このモデルは、テキスト、画像、動画データを同時に処理できる非常に強力なツールです。特に電商(E-commerce)や短動画において優れた性能を発揮しています。以下の特徴があります:
主な特徴
- 多モーダル対応:テキスト、画像、動画データを一度に処理し、複合的な理解を行います。
- 電商商品説明:商品画像や説明文から、商品情報を適切に理解し、魅力的な商品説明を生成できます。
- 短動画内容理解:動画の内容を解析し、文脈に沿った理解を提供することができます。
- 高性能なマルチタスク処理:電商や短動画などの複雑なタスクに対応できるため、マーケティングやコンテンツ制作の支援に非常に有用です。
リソースリンク
- GitHubページ: https://github.com/bytedance/Valley
- モデル(Hugging Face): https://huggingface.co/bytedance-research/Valley-Eagle-7B
このモデルは、特に電商のコンテンツ生成や短動画の理解を効率化し、ビジネスやマーケティングに強力なツールを提供します。