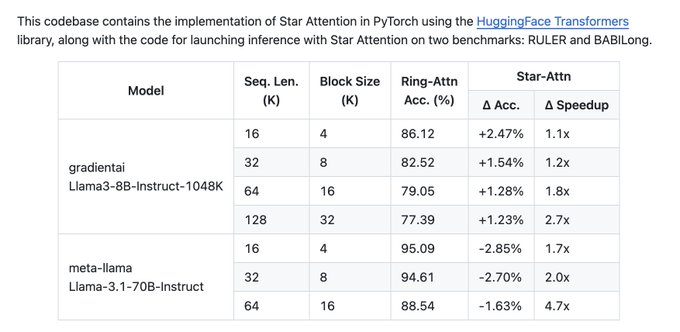
Star-Attention:NVIDIAが長文テキスト処理におけるLLMの推論効率を向上させるためにオープンソース化した最適化ソリューション
この技術は、95~100%の精度を維持しながら、推論速度を11倍に向上させることができます。
主な特徴:
- 追加トレーニング不要: 既存のTransformerモデルと直接互換性があり、即時利用可能
- 他の最適化手法との組み合わせ可能: Flash Attentionなどと組み合わせてさらに効果を発揮
- 長いテキストの効率的処理に最適: 大量の長文テキストを扱うアプリケーションに特に有効
仕組み:
- 長いシーケンスを複数のブロックに分割
- 各ブロックの先頭に「アンカーブロック」を追加
- ローカル注意メカニズムを用いて各ブロックを並列処理
- 計算量と通信コストを削減し、推論速度を向上
詳細はGitHubリポジトリをご覧ください。